Building a data platform
for machine learning operation
Content
- Who am I
- Problem definition
- MLOps vs DevOps
- Containers & Kubernetes
- KubeFlow
- Conclusions
Julien Bisconti
Software Engineer
specialized in Google Cloud
PART I
problem definition
how to:
- train
- build
- deploy
- monitor
Machine Learning models
in a repoducible manner
at scale ?
Hidden Technical Debt in Machine Learning Systems
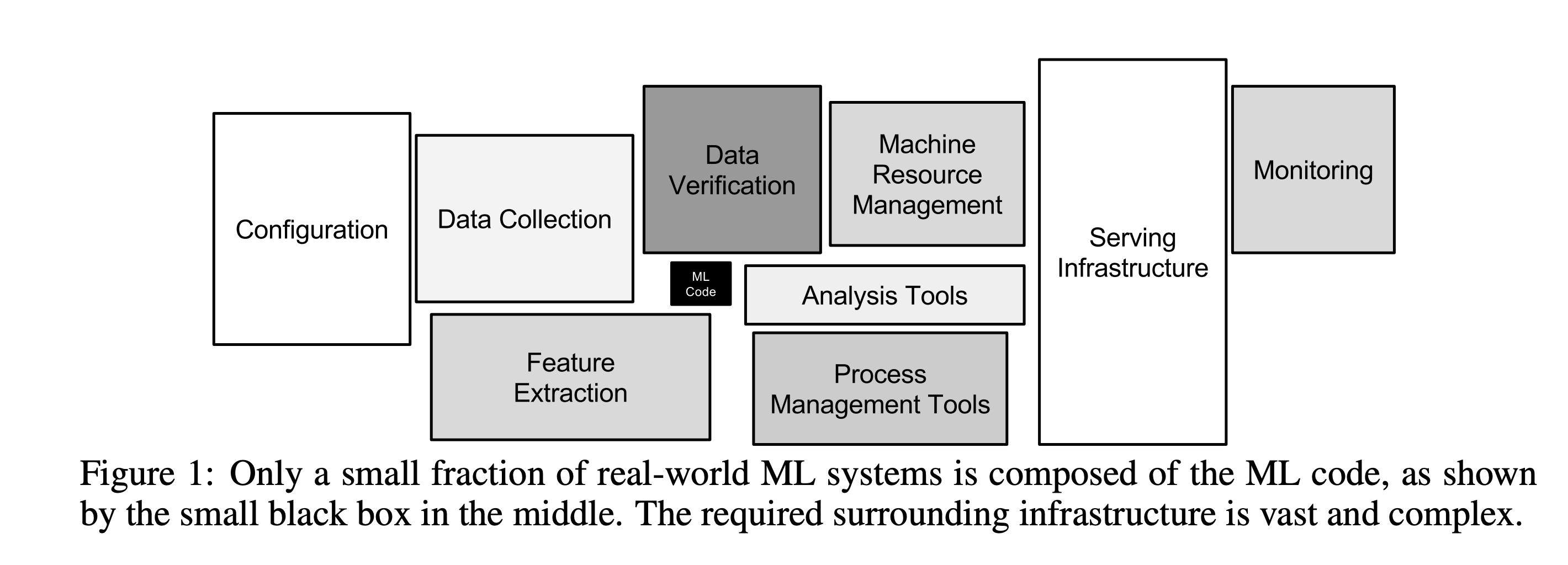 Source: D. Sculley, et al.: Hidden Technical Debt in Machine Learning Systems
Source: D. Sculley, et al.: Hidden Technical Debt in Machine Learning Systemscost of context switching
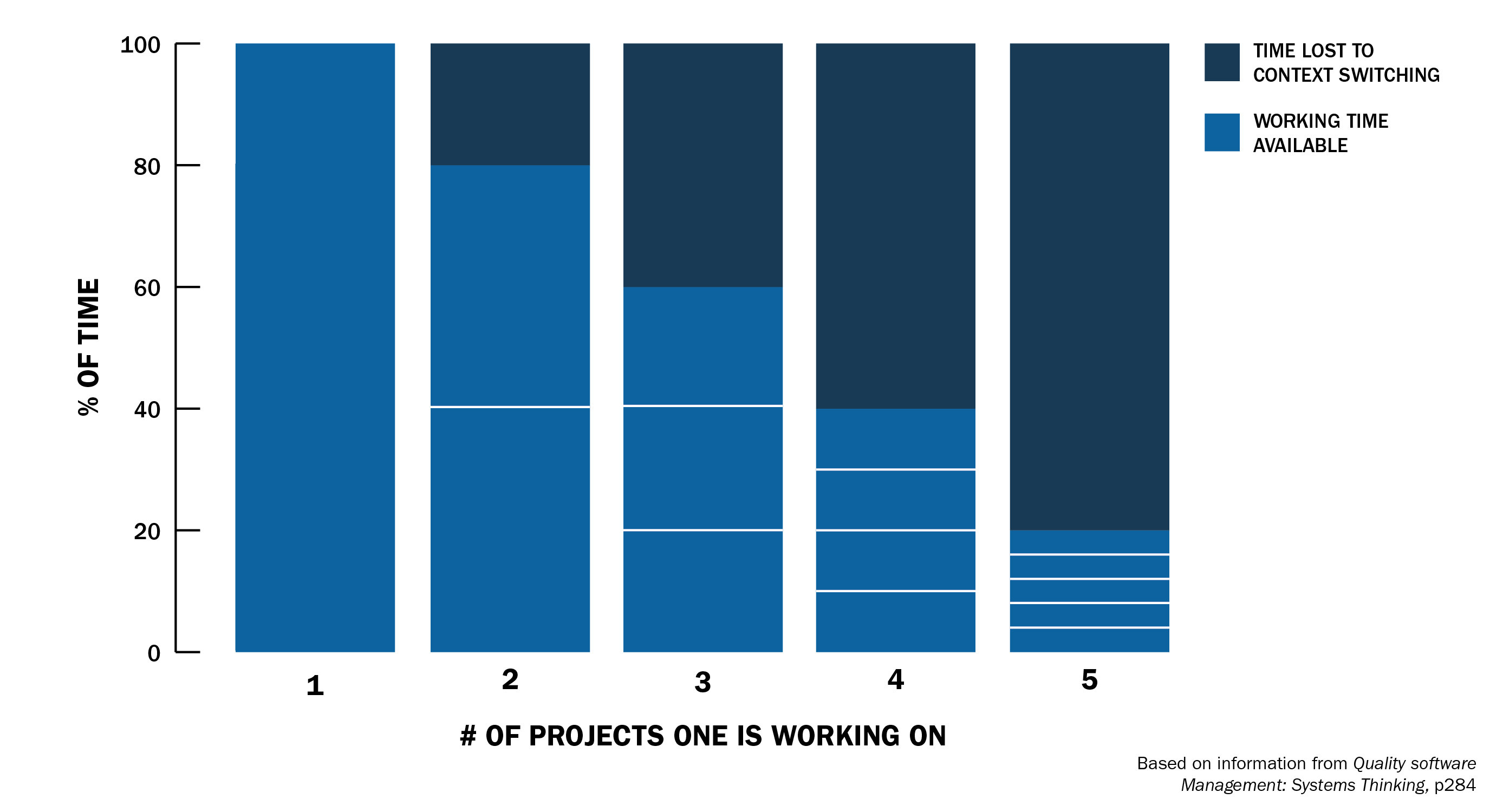
Mental limitations
- # decisions / day
- # things to remember
- speed of memory / reflexes
Strategy
People
Assumptions

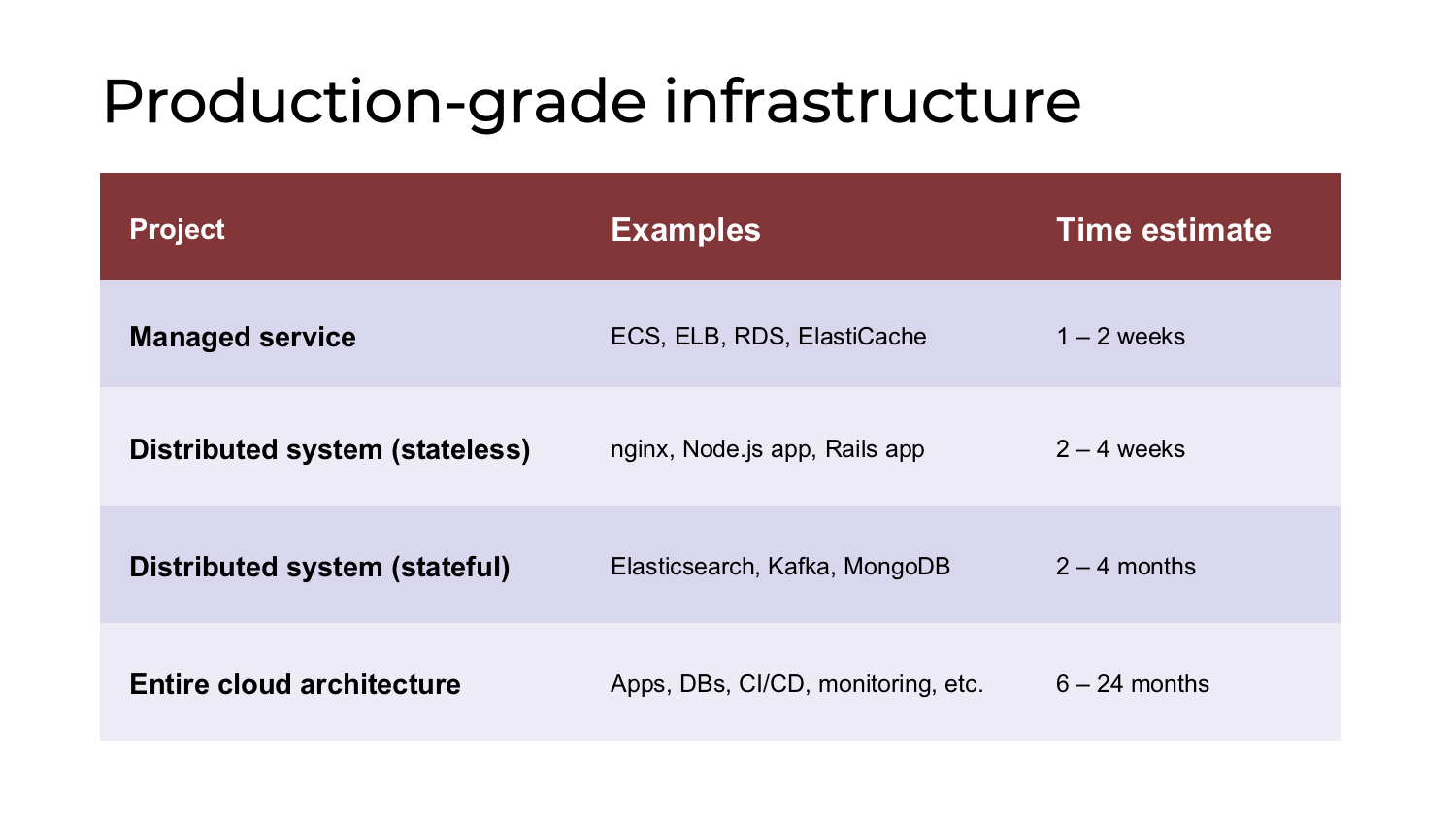
Yevgeniy Brikman - Lessons from 300k+ Lines of Infrastructure Code
build OR buy

We could build it
BUT
spending time on the business
makes more sense financially
 repository
repositoryPART II
MLOPS
vs
DevOps
#thisisdevops

Yevgeniy Brikman - Lessons from 300k+ Lines of Infrastructure Code
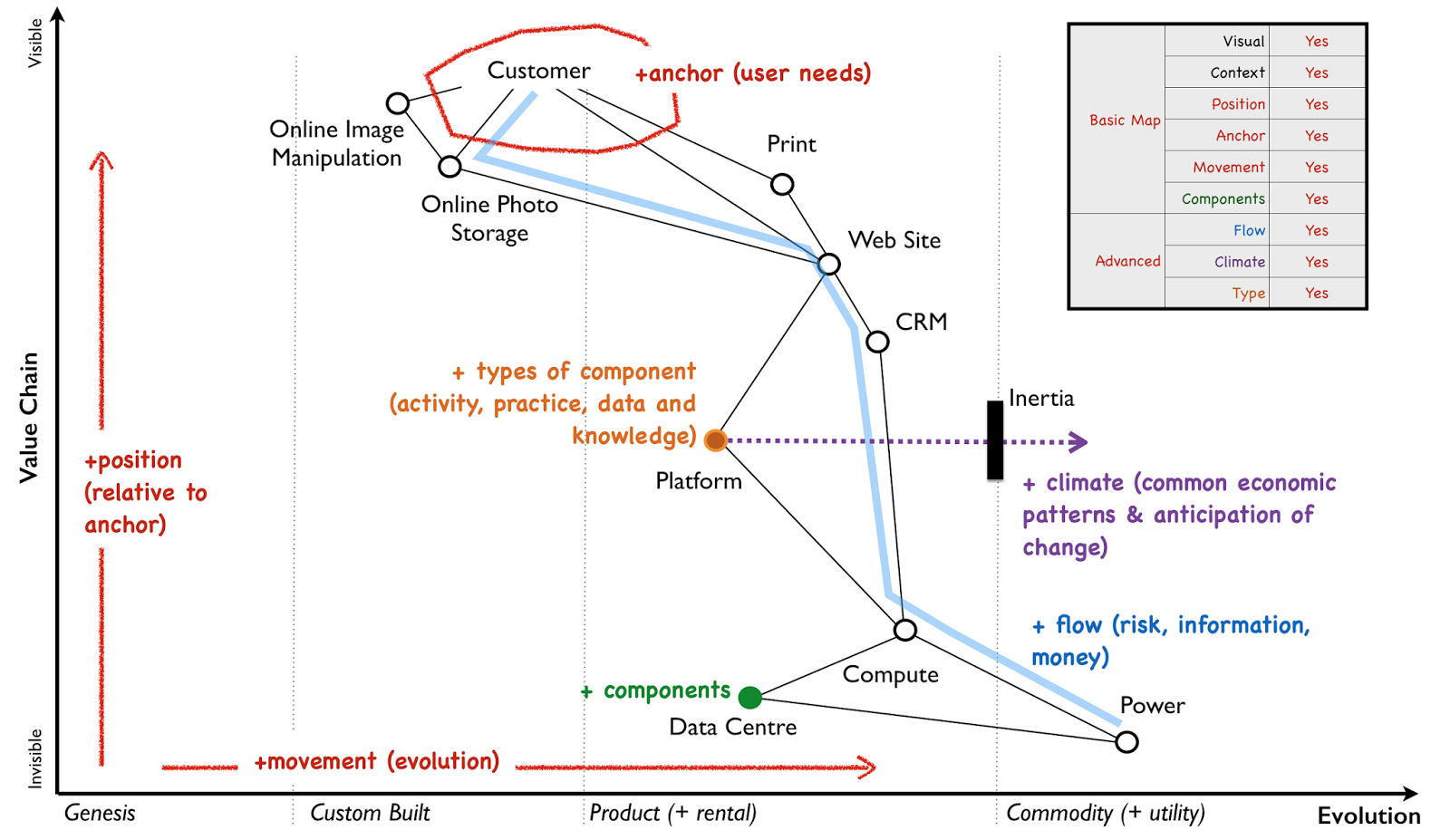
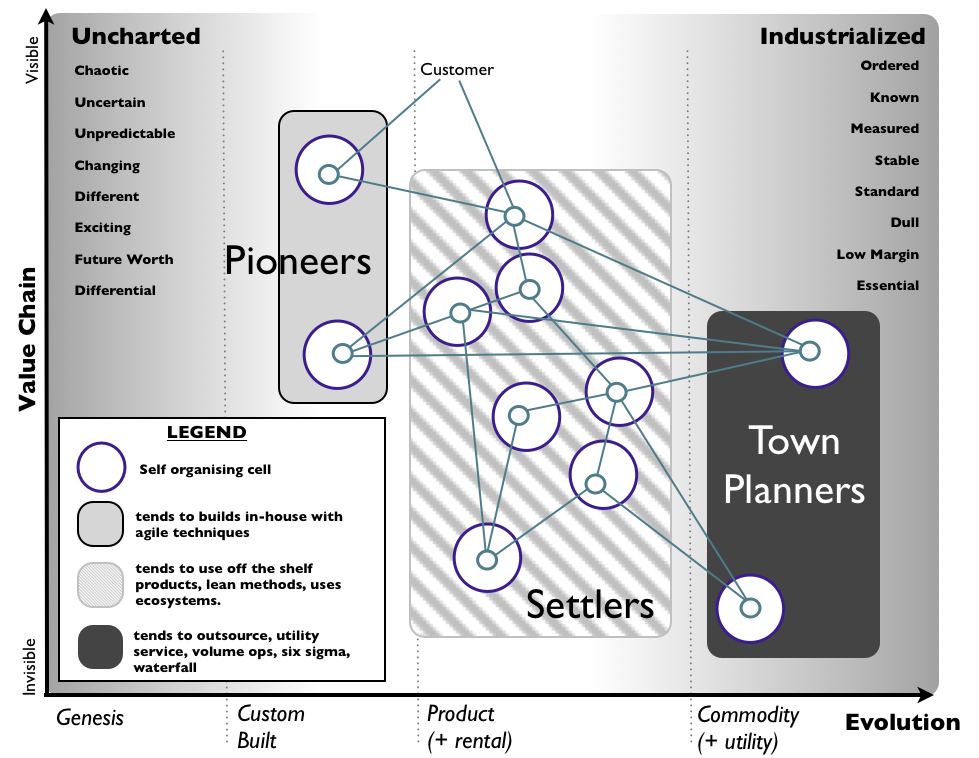
ML platform assembly kit
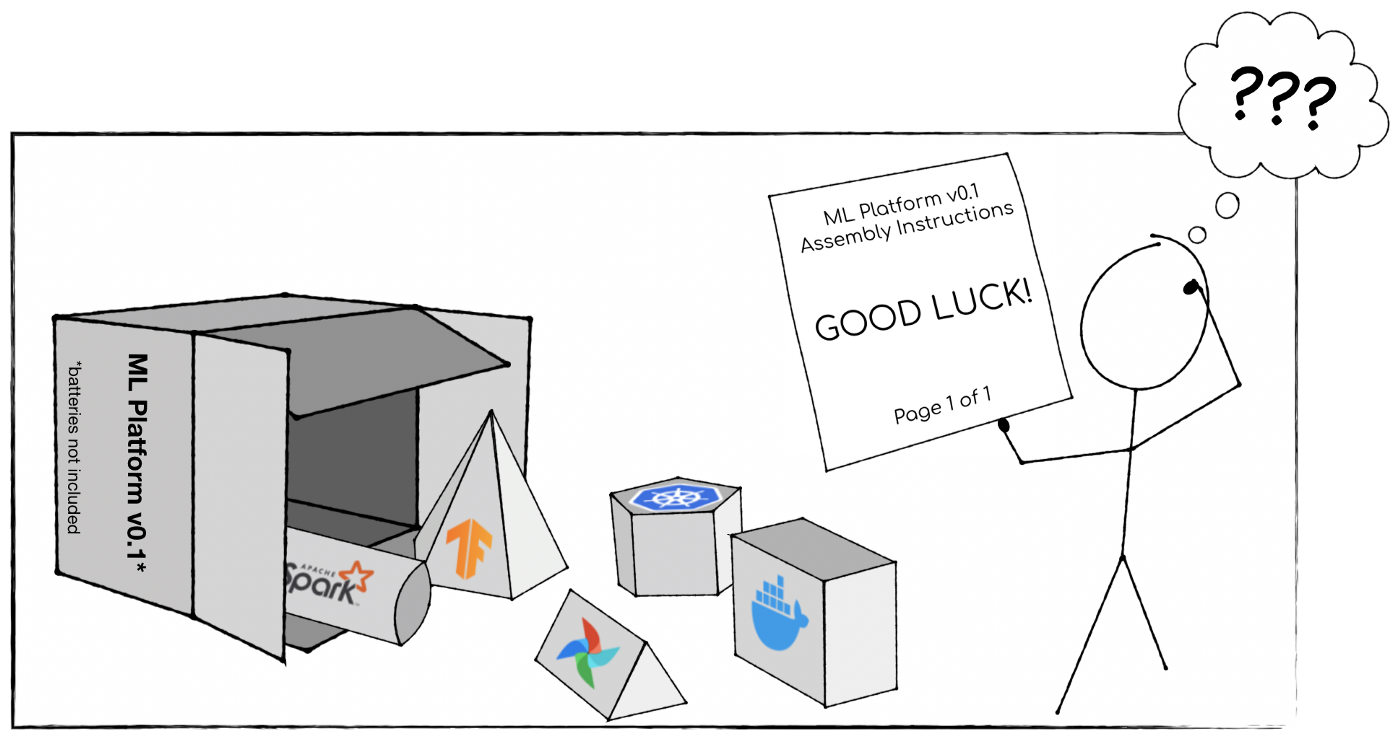 Source: article by Clemens Mewald
Source: article by Clemens Mewaldhow different is ML
- Various hardware
- Resources heavy
- Various cycles
- Many languages
- Dependencies
- Explainability >< debugging
- Composability of models
- Huge amount of data
And after a while
More models, more requests and more data
Consistency is key
source

PART III
Containers & Kubernetes
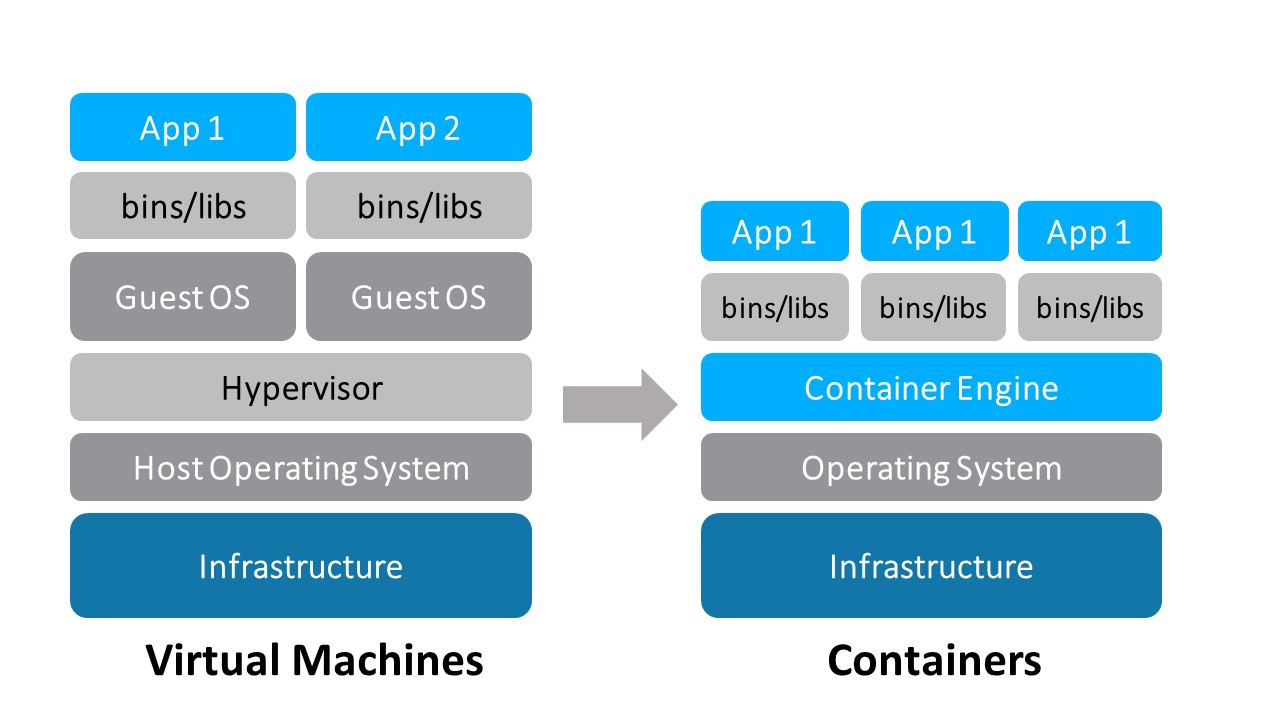
Containers
container image: zip file of app + dependencies
docker: program that runs the image
each container runs in its own namespace
Deployment
Containers: lightweight VMs
- 12 factor app
- easier deploy
- reproducible build
but ...
how to orchestrate containers across many computers ?
Deployment concerns
- Scaling up and down
- Redundancy
- Scheduling / Orchestration
- Service Discovery
- Resiliency
- Rolling out and back
- Health checks
- Secret and config
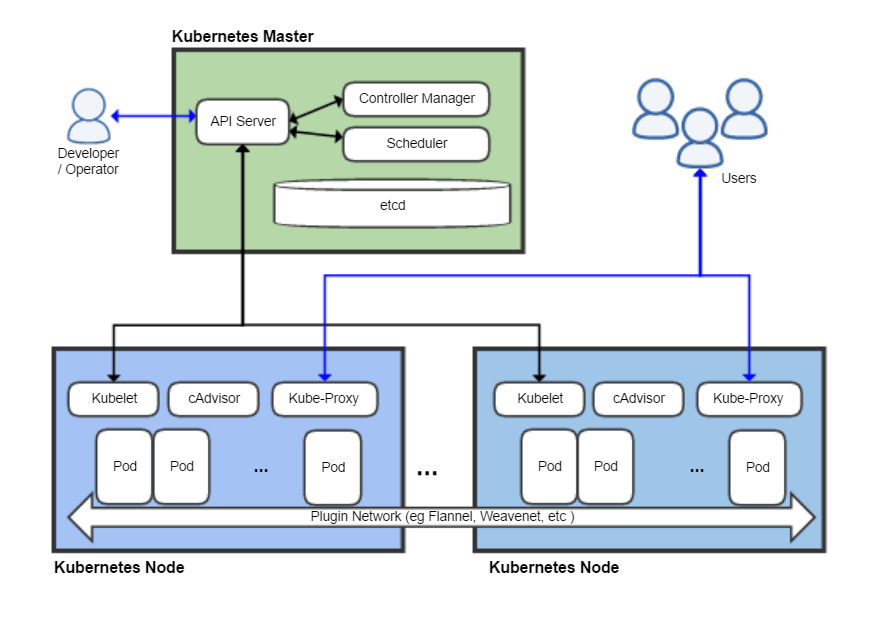
Kubernetes
KUBEFLOW
The Machine Learning Toolkit for Kubernetes
KF Pipelines goals:
- End-to-end orchestration
- Easy experimentation
- Easy re-use
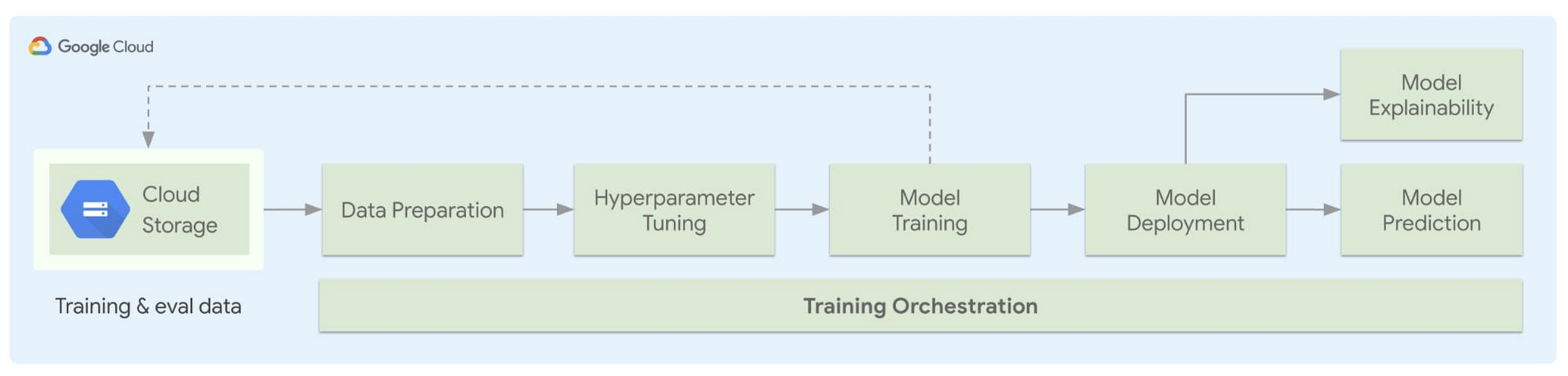
Deploy kubeflow
GCP AI PlatformLocal installation
CONCLUSIONS
- Consistency is key
- Context switching is expensive
- Re-use = able to share = caring
- More models & data tomorrow than today
Resources
THANK YOU
and I'm sorry 🙏
If you had to maintain my code
I hope you learned more by maintaining it
than me by writing it
Slides made with Reveal.js and hugo-reveal